TensorFlow で学習させて、NumPy 等を使い学習済みのパラメタをデータを bfloat16 の Python の list に落とすことに成功しました。そのデータをもう一度 float に戻した上で NumPy で計算するとうまく予測してくれそう(多くの人がそう信じていろんなところで 実験しているはず)なこともわかりました。
次のステップは NumPy からも離れて bfloat16 をPython で直接扱うようにしてみましょう。その為に bfloat16 の足し算と掛け算をするプログラムを組みます。
掛算のプログラム
浮動小数点数の計算なので足し算より掛け算の方が楽です。Python のソースコードを次に掲げます。まずは正しく動くことが重要なので最適化されていません(いいわけ)。誰か賢い人、より最適化してみてください。あるいは C でオフロードしてみてください。そのまま組み込みシステムの世界で使えるようになるかもしれません。
bit16 というタイプヒントを使っていますが、気にせず行きましょう。最終的には Polyphony というコンパイラを使って FPGA で動くようにするための布石です。タイプヒントはあくまでヒントなのでPython 実行時は見事に無視してくれます。
足し算のプログラム
桁合わせがあるので掛算よりちょっと複雑です。浮動小数点数の計算は精度があまりにも出なくなった場合ゼロにまるめたり、最後のビット等を微妙に切り上げたりというテクニックを使って、精度をなるべく落とさないようにするのが定石です。が!ここでは一切そんなことはしていません。動けばよかろう!(きっぱり)なのです(ここではね)。
#print('sub_add', x_sign, x, b_sign, b, e)
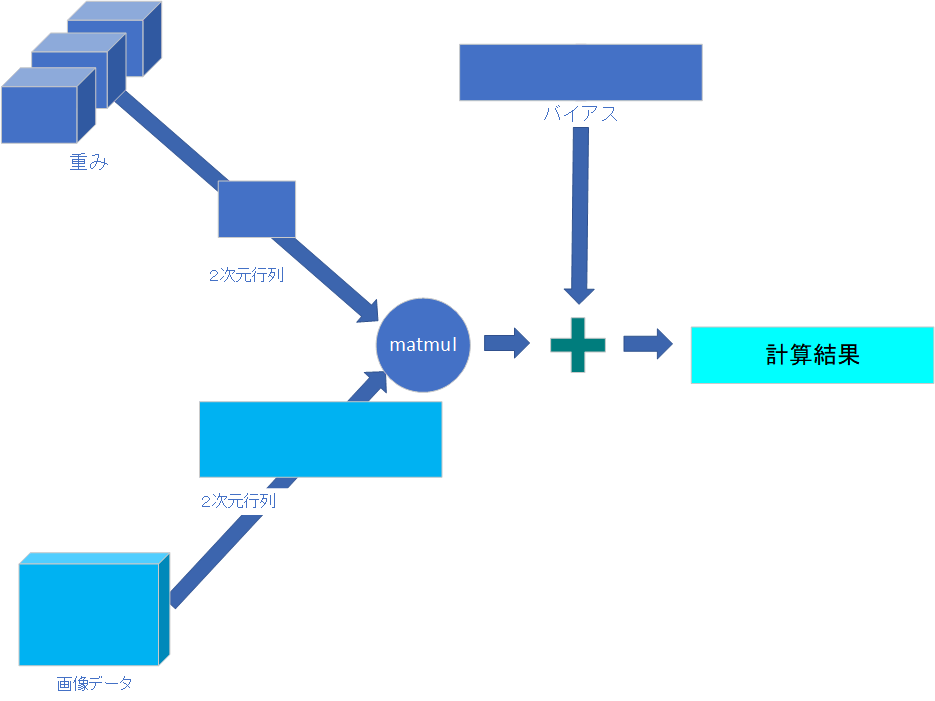
積和演算
ここまで来ると積和演算が簡単にできますよ(最終的には使わなかったりするのですが)。
その次のステップは Python でテストベンチを書いて動かすことです。テストベンチ?!
リンク集
もう絶版?になっているみたいですが、次の「ディジタル・ハードウェア設計の基礎と実践」がプログラミングに役に立ちました。